

自從今年初YOLO原作者Joseph Redmon宣佈要停止並退出CV研究領域之後,不少人對於YOLO這金字招牌虎視耽耽,認為只要貼上了YOLO mark便能睥睨群雄登上電腦視覺的最高峰,於是,就在官方認證的YOLOV4發表沒多久,馬上就有YOLOV5猝不及防的出現,宣稱是下一版YOLO的接班人。
雖然檢測的桂冠爭奪得如此激烈,但受益的還是我們這些寫不出高端技術只會用它們的使用者,所以本文主要內容是介紹訓練YOLOV4及V5的方法及步驟,讓您也可以自行訓練出最新版本的YOLO模型。
YOLOV4
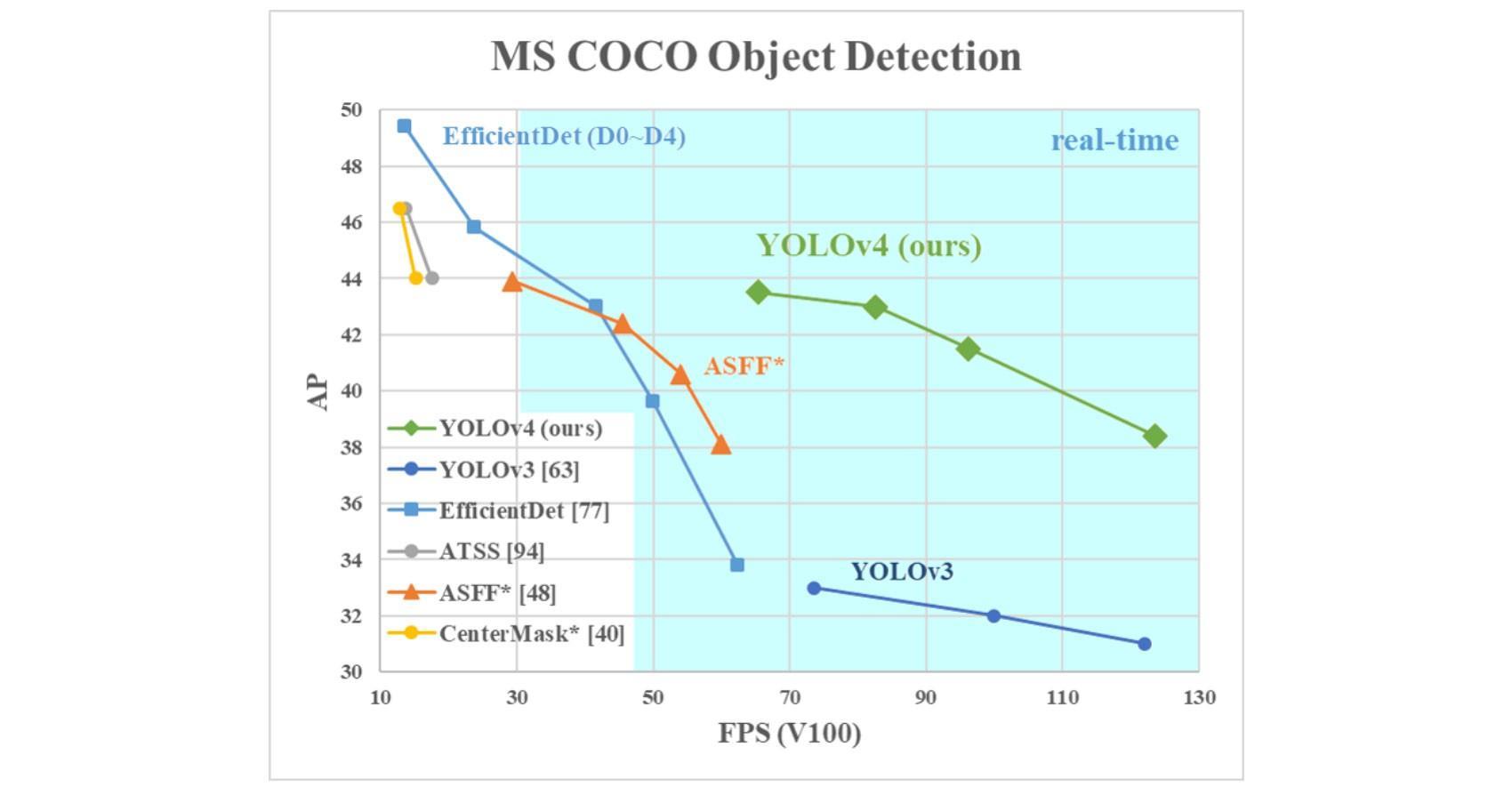
受益於YOLO-Alexey優化的強健體質,加上台灣中研院資科所的廖弘源和王建堯提供的CSPNet detector(V4的backbone稱為CSPDarkNet-53),因此最終得到YOLO官方Joseph Redmon的認同,成了第四代接棒者。如下圖所示,X軸FPS(愈右邊愈好)Y軸AP(愈高愈好)的圖表中,YOLOv4位於最右上方,代表它是目前兩種性能兼顧的最佳方案。
下方一步步介紹如何使用自己的dataset來訓練YOLOv4及v5模型。v4訓練的步驟方法與V3幾乎相同,差別在於模型定義檔的內容,以及訓練指令參數有異。v5由於改用PYTorch則已是完全不同的架構了,但兩者使用的dataset格式是相同的。
步驟一: prepare training dataset
先用Labelimg(https://github.com/tzutalin/labelImg.git)工具繪製bounding box,下方的實作,我使用檢測人體的head以及body為例,標記名稱為person_head以及person_vbox。

輸出的xml標記檔請存放於labels目錄,圖檔則放置於images目錄,最後,你的dataset目錄架構如下,僅有兩個目錄:

步驟二: 執行Make Cofig Yolov4
為了方便快速訓練,我製作了一套工具可快速轉換及產生設定檔:
依序執行下列python檔:
0_extract_all_labels_to_imgs.py | 將所有標記框crop下來並依其類別存放,可檢驗標記框是否正確。(此步驟非必要) |
1_labels_to_yolo_format.py | 將XML標記轉換為YOLO格式 |
2_images_to_list.py | 產生所有的image列表 |
3_anchor_boxes.py | 計算取得稍後要用的anchor box sizes |
4_split_train_test.py | 將所有圖檔切分為train及test兩類 |
5_make_config.py | 製作YOLO config檔 (obj.names, obj.data) |
6_make_yolo_cfg.py | 製作YOLO模型定義檔(yolov4.cfg) |
執行上述的步驟後,會產生如下的資料夾及檔案:

images: 原先您放置圖檔的folder
labels: 原先您放置xml標記的folder
yolov4_config: 定義於cfgFolder參數,obj.data, obj.names, yolov4.cfg皆會存放於此
weights: 存放稍後訓練時會產生的權重檔
步驟三: 開始訓練
darknet detector train {obj.data檔的path} {yolov4.cfg檔的path} {pre-trained weights的path} -dont_show -mjpeg_port 8090 -gpus 0,1
參數說明:
{obj.data檔的path}:即yolov4_config path下的obj.data
{yolov4.cfg檔的path}:即yolov4_config path下的yolov4.cfg
{pre-trained weights的path}:從YOLOV4官方網站下載預訓練檔path,或從上次最後訓練的weights檔path。
dont_show:傳承自YOLO-Alexey優化版的功能,若不加上此參數,則會顯示training過程的loss變化曲線圖,但如果你是遠端ssh連線訓練,則可加上此參數不顯示。
-mjpeg_port 8090:傳承自YOLO-Alexey優化版的功能,可於訓練主機的8090顯示訓練曲線圖表。
-gpus 0,1:指定要在那些GPU training。
步驟四: 推論測試
除了觀察loss變化之外,亦可隨時取用weights目錄下的yolov4_last.weights試試目前推論的結果,請參考附錄一修改自官方的darknet_video.py,可輸入一段影片並產生推論結果。下方為YOLOV4與YOLOV3的比較,會發現YOLOV4檢測率的確較高,但容易出現大框,據網路上說明,是因為在使用COCO預訓練時有啟用iscrowded(COCO dataset有此標簽用以代表聚集物件)。
YOLOV5
YOLOV4發表未滿兩個月,便突然出現了打著YOLOV5名號的新模型,號稱較前代改進的幅度更大。YOLOV5包含了一系列從小包到大型的5-s, 5-m, 5-l, 5-x模型,而與YOLOV4相對的是最小最弱的5-s,但5-s不但檢測速度更快更準,模型大小還縮小至只有十分之一,甚至還小於YOLOV3-Tiny。可能由於原作者Roboflow也是與YOLO淵源頗深,先前所開發的YOLO Pytorch版大受歡迎之故,否則,這麼優秀的模型另外起個新名字也應能大受矚目。
YOLOV5的dataset準備
所需格式與傳統YOLO相同,都是一個圖檔搭配一個txt標記檔,但是YOLOV5不用產生train.txt及test.txt這兩個image list,只要將圖檔+txt檔的路徑設定給train及val這兩個參數即可。另外,YOLOV5還有一個很好的改良,它分離了dataset定義和模型定義成為兩個不同的設定檔案,不再像以往是單獨一個yolov4.cfg定義了dataset及model兩種設定,因為dataset我們很少去變更,卻很常用相同的dataset去訓練出不同的模型。
所以,您只要執行前述YOLOV4的程式碼1_labels_to_yolo_format.py,便可產生出yolo資料夾。這便是YOLOV5需要的dataset了。(本文先用train與val共用同一dataset來訓練,未來會加入script自動產生這兩個dataset)
YOLOV5資料庫設定檔
將下方的藍色內容修改後,存成dataset.yaml(檔名可自取),其中train及val能接受path以及text檔兩種參數,所以也能給予舊版本的train.txt, test.txt檔案列表。
train: /DATA1/Datasets_mine/labeled/crowndHuman_2_classes/yolo
val: /DATA1/Datasets_mine/labeled/crowndHuman_2_classes/yolo
# number of classes
nc: 2
# class names
names: ['person_head', 'person_vbox']
YOLOV5模型設定檔
從yolov5/models/下,選擇一個(本例為yolov5s.yaml)範本複製過來,修改內容如下,藍色為需要修改的地方。Anchors參數可直接用上述製作YOLOV4的script:3_anchor_boxes.py產生一組anchor boxes(注意,YOLOV5-s的建議尺寸是640×640非YOLOV4傳統的618×618 ,但依官方說明,該尺寸在訓練時可自行指定)。
# parameters
nc: 2 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [7,12, 16,33, 28,68] # P3/8
- [36,160, 57,105, 63,291] # P4/16
- [106,205, 124,466, 257,601] # P5/32
# yolov5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 1-P1/2
[-1, 1, Conv, [128, 3, 2]], # 2-P2/4
[-1, 3, Bottleneck, [128]],
[-1, 1, Conv, [256, 3, 2]], # 4-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 6-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 8-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 6, BottleneckCSP, [1024]], # 10
]
# yolov5 head
head:
[[-1, 3, BottleneckCSP, [1024, False]], # 11
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1]], # 12 (P5/32-large)
[-2, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 1, Conv, [512, 1, 1]],
[-1, 3, BottleneckCSP, [512, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1]], # 17 (P4/16-medium)
[-2, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 1, Conv, [256, 1, 1]],
[-1, 3, BottleneckCSP, [256, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1]], # 22 (P3/8-small)
[[], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]

訓練過程也會將數值分別儲存到runs/目錄下,可透過tensorboard讀取,另外也會儲存到results.txt,可用Excel直接讀取繪製圖表。

在第一和第二個batch結束後,會產生如下的圖檔供參考:


Predicted for Test
訓練結束後,會自動產生報告圖表result.png。下方圖表mAP未明顯上升原因,在於yolov5設定檔中我沒有將train及test分開,因此訓練時的test size與train一樣大,造成mAP上升緩慢。如果您有分別指定不同的train及test dataset,會發現其mAP與Loss呈現明顯的升降。

最後
我作了YOLOV3-Tiny, YOLOV3, YOLOV4, YOLOV5-s的比較於此影片中,若要論檢測率,還是以YOLOV4為最佳,但是YOLOV5還有一系列參數更大mAP數字更優異的版本,甚至效果最佳的yolov5x其file-size比起YOLOV4還要更小。此外,YOLOV5雖未獲官方承認,但其對上一代改進的程度比起V4的幅度更大,在訓練及使用上更加的簡單方便。
後續
關於YOLOV5的後續爭論,可參考此篇「https://blog.roboflow.ai/yolov4-versus-yolov5/」YOLOV5原作者公司Roboflow的解釋,以及此篇「https://medium.com/@riteshkanjee/yolov5-controversy-is-yolov5-real-20e048bebb08」第三方對此事件的分析。

你必須登入才能發表留言。