
要描述一張相片的色彩,我們可以利用color space分離其色彩channels後,分別計算其平均、變異,就能將這些數值作為描述其色彩的特徵,那是否也有類似的方式,能夠透過一組數值就能描述物件的外形呢?
可以的,要描述物件的形狀給電腦認識,最簡單的方式是使用所謂的「moments」,在影像處理和電腦視覺領域,「Image moments」這個名詞指的是一串用來描述物件形狀的數值,例如該物件的面積、中心點座標(centroid)、旋轉角度…等等,這些數值可讓我們得以量化方式定義該物件的形體,並用以衡量不同物件間相似的程度。
Moments是最早應用於辨識平面物體的方法之一,直到目前也仍持續應用於電腦視覺領域,計算moments的模型有很多種,以下介紹最具代表性的Hu moments與Zernike 兩種moments。針對moments詳細的定義請參考維基的說明:https://en.wikipedia.org/wiki/Image_moment。
Hu Moments
早在半個多世紀前的1962年,Ming-Kuei Hu博士(sorry我查不到他的中文姓名)在其「Visual Pattern Recognition by Moment Invariants」paper中首度提出了最適合用於描述相片中物件的七個moments,他所提出的這七個moments改良自標準的geometric moments(幾何矩),由於是透過normalized central來計算moments,因此物件在經過旋轉、移動、縮放、鏡像…等處理後moments仍能維持不變,比起原來標準的moments更適合作為描述及比較物件的相似度,您可參考https://www.youtube.com/watch?v=uEVrJrJfa0s這影片針對Hu moments的簡要說明。
這七個Hu moments是:
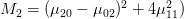
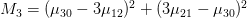
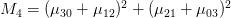
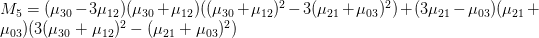
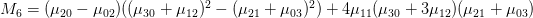
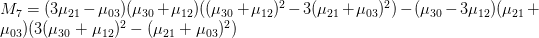
上方各個u值指的是central moments,限於個人能力無法完整的說明其計算原理,如果您有興趣深入的話,可自行Google並study這七個數值的計算。
由於OpenCV預設就有提供標準及Hu Moments相關指令,因此我們很輕易就能取得某個shape的Moments值。其中的Hu moments由於是依據物件中心點計算出來的,因此在經過旋轉、移動、縮放、鏡像…等變形後這些數值仍能保持不變,然而在現實的世界中,一個正確可靠且變形後仍能維持固定的物件中心點並不是那麼容易求得,主要是因為圖片中有很多的干擾噪點、雜物、以及不純的背景,在圖形經過旋轉、移動、縮放、鏡像…等變形後,物件中心點稍稍有差異,都會放大干擾並影響到中心點的計算,算出的moments就不盡相同。
另外,Hu Moments還有一個使用上的限制,就是它比較適合處理如下圖有著明確輪廓外形及物體形狀的binary image(黑白),因此我們必須先將相片進行thresholding處理抓取出需要的輪廓後,再交由Hu Moments計算。

計算Hu moments
取得Hu moments的方式是,先透過cv2.moments取得標準的image moments,再把它們當作參數傳入cv2.HuMoments來計算出七個Hu moments值,在機器學習中可利用這些數值作為該物件的features。我們以上面的瓢蟲圖片為例,計算其moments如下:
import cv2
# 讀入圖檔並轉為灰階
image = cv2.imread(“bug.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 計算標準的moments
print cv2.moments(image)
—> 得到
{‘mu02’: 2233333577834.0234, ‘mu03’: 129557986781984.0, ‘m11’: 4964349911095.0, ‘nu02’: 0.0007141833695733439, ‘m12’: 2108258440337853.0, ‘mu21’: 22741780377672.875, ‘mu20’: 2364239793269.659, ‘nu20’: 0.0007560450256044092, ‘m30’: 3922564850335147.0, ‘nu21’: 9.725112479138234e-07, ‘mu11’: -208680548.3515625, ‘mu12’: 18093118070.0, ‘nu11’: -6.673260934475954e-08, ‘nu12’: 7.737195831062893e-10, ‘m02’: 6747239328750.0, ‘m03’: 3315568524577530.0, ‘m00’: 55920614.0, ‘m01’: 15887743110.0, ‘mu30’: 61916149919.5, ‘nu30’: 2.6477325532238706e-09, ‘nu03’: 5.540313788547935e-06, ‘m10’: 17473920793.0, ‘m20’: 7824442856849.0, ‘m21’: 2245633058963161.0}
# 計算Hu moments,我們會得到七個數值
print cv2.HuMoments(cv2.moments(image)).flatten()
—> 得到
[ 1.47022840e-03 1.75241606e-09 6.87897527e-12 4.24169017e-11
7.24552167e-22 -1.77564672e-15 1.23212849e-24]
測試一下,將圖形改變一下,看看其moments的變化。
#將圖形寬度縮小為250px
import imutils
resized = imutils.resize(image, width = 250)
計算出的標準momnets與原先的差異很大
print cv2.moments(resized)
—> 得到
{‘mu02’: 56807612771.22003, ‘mu03’: 1316052668211.164, ‘m11’: 125642235536.0, ‘nu02’: 0.0007141406514037825, ‘m12’: 21289660587448.0, ‘mu21’: 230997387372.47852, ‘mu20’: 60137789335.889404, ‘nu20’: 0.0007560050133293632, ‘m30’: 39668345750417.0, ‘nu21’: 9.723633653354928e-07, ‘mu11’: -5520177.506500244, ‘mu12’: 175483997.8173828, ‘nu11’: -6.939533221071715e-08, ‘nu12’: 7.386845912897383e-10, ‘m02’: 171022046753.0, ‘m03’: 33526486098611.0, ‘m00’: 8918902.0, ‘m01’: 1009290515.0, ‘mu30’: 608411114.1484375, ‘nu30’: 2.5610535477916638e-09, ‘nu03’: 5.539808982155727e-06, ‘m10’: 1110324533.0, ‘m20’: 198363388023.0, ‘m21’: 22677037009498.0}
相反的,Hu momnets值與原先的幾乎一樣
print cv2.HuMoments(cv2.moments(resized)).flatten()
—> 得到
[ 1.47014566e-03 1.75264406e-09 6.87865447e-12 4.24083996e-11
7.24317503e-22 -1.77540564e-15 1.19632159e-24]
而且水平及垂直翻轉後,Hu momnets值保持不變
print cv2.HuMoments(cv2.moments(flipped)).flatten()
—> 得到
[ 1.47022840e-03 1.75241606e-09 6.87897527e-12 4.24169017e-11
7.24552167e-22 -1.77564672e-15 1.23212849e-24]
Zernike Moments
接下來我們看看另一種moments演算法:Zernike moments。它與Hu moments類似也是屬於描述物件形態的工具,是由Michael Reed Teague在1980年首度在其paper(https://www.osapublishing.org/josa/abstract.cfm?uri=josa-70-8-920)所提出,在這之前,業界最常用的就是Hu moments,但在Zernike moments提出後,其描述形狀的功力更上層樓,因此也經常被使用。
Zernike moments是運用幾何學中正交(orthogonal)表示兩線成直角狀態的原理,將這個概念擴充,用以形容物體不受外界影響的某種特性,同時也用正交表示該物體:沒有冗餘、沒有重疊、或者無關等等特性。在計算機領域,如果某種編程語言或某個數據對象的引用不影響其他事件,就可以將之稱為正交的。(註:本段引用自http://www.searchstorage.com.cn/whatis/word_3344.htm)
前述提到的Hu moments,它的七個數值之間相互關聯且皆導源自物件中心點central point的值,某個moment值若變動其它moments也會跟著改變,然而Zernike moments的特性是,其所計算出的數據彼此之間是獨立的,即「no redundancy of information between moments」,不會因此某moment值變動而影響到其它的moments值,所以它比起Hu moments更適合描述與重建物件,且較不會受到雜訊的影響,但相反的需要運算成本也會比較高。關於Zernike moments可參考此篇的說明:https://www.slideshare.net/SandeepKumar622/zernike-moments
使用Zernike moments
目前OpenCV沒有支援Zernike moments,因此必須另外引用mahotas模組。我們使用剛剛的瓢蟲圖片,看看Zernike所傳回的moments:
引入mahotas
import mahotas
Zernike需要2個參數,第一個為半徑R,第二個為degree。
print mahotas.features.zernike_moments(image, 13, degree=8)
—> 得到
[ 0.31830989 0.0984956 0.22791679 0.08110641 0.11244051 0.01941635
0.09895417 0.04575301 0.07780053 0.1021046 0.01687787 0.00380097
0.03716546 0.06200727 0.00392502 0.04462806 0.03706978 0.13394823
0.02967233 0.14083293 0.10000021 0.00236996 0.05249373 0.12757217
0.00288343]
關於mahotas.features.zernike_moments的第一個參數半徑R,Zernike會將物件中心點置於該半徑R的圓心上,並且只處理此圓內的部份,任何超過此圓的皆會被忽略。因此,R的最佳值是剛好能讓該物件緊密貼合在圓內,像這樣:
使用Zernike moments來比對葉子類型
知道Mahotas的Zernike moments指令後,接下來我們試著在實際生活中應用看看。我在網路上找到這張植物葉片形狀的說明:
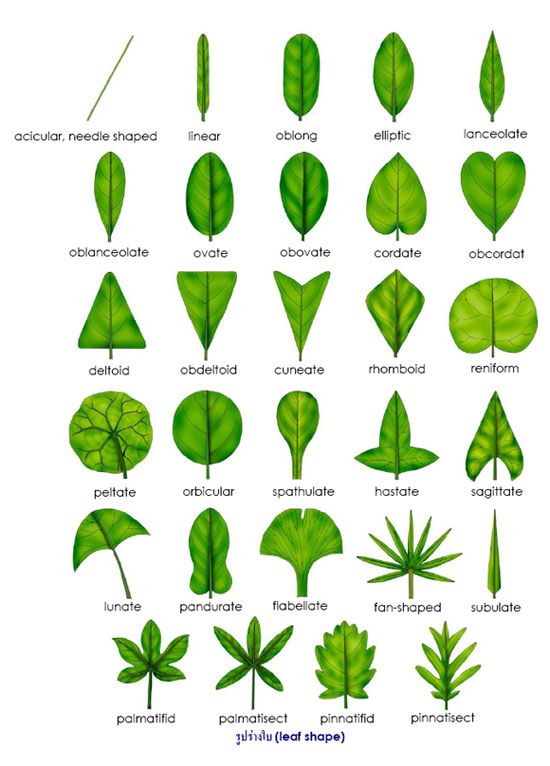
刪除文字部份後,將整張圖片儲存為leaves.png,以下我稱此張圖片為「葉片類型圖」。
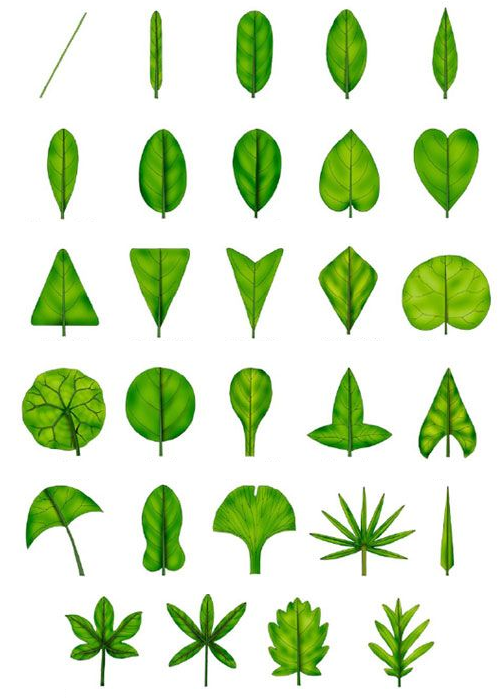
接下來,也是在網路上找8張不同的葉子相片如下(下列八張圖片我稱為「目標圖片」),看看可否讓電腦不透過機器學習,直接計算moments就能判斷這些葉片的類型。

執行步驟:
- 傳入葉片類型圖及要比對的目標圖片。
- 灰階、模糊、兩極化後計算目標圖片的Zernike moments。
- 將葉片類型圖中各個葉片抓取出來:
先將相片進行灰階、模糊、兩極化(thresholding)。 - 使用openCV的findContours(找出輪廓)指令,取出各個葉片。
- 計算葉片類型圖中各個葉片的Zernike moments。
- 應用歐式距離方法,計算每個葉片與目標葉片的差異。
- 取葉片類型圖中差異最小的那個葉片,就是與目標葉片最相似的。
程式說明:(https://github.com/ch-tseng/detectLeaf)
#載入必要模組
from scipy.spatial import distance as dist
import numpy as np
import mahotas
import cv2
import imutils
import argparse
#接收葉片類表圖及目標葉片的path
ap = argparse.ArgumentParser()
ap.add_argument("-s", "--source", required=True, help="Path to the source of shapes")
ap.add_argument("-t", "--target", required=True, help="Path to the target image")
args = vars(ap.parse_args())
#這個function用來取得相片中的葉川,並傳回其Zernike moments
def describe_shapes(image, title):
# 此陣列用來放置相片中各物件的moments
shapeFeatures = []
#將相片進行灰階、高斯模糊及二極化處理。
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = (255-gray)
blurred = cv2.GaussianBlur(gray, (3, 3), 0)
thresh = cv2.threshold(blurred, 50, 255, cv2.THRESH_BINARY)[1]
#針對圖片進行侵蝕(Erosion)與膨脹(dilation),可消除過於細膩的邊緣形狀及內部的小空洞。
thresh = cv2.dilate(thresh, None, iterations=4)
thresh = cv2.erode(thresh, None, iterations=2)
cv2.imshow(title, thresh)
#找出輪廓
(cnts, _) = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
#依次檢視各個輪廓
for c in cnts:
#產生該輪廓的mask,並繪出其邊緣
mask = np.zeros(image.shape[:2], dtype="uint8")
cv2.drawContours(mask, [c], -1, 255, -1)
#取得該輪廓四邊形外框的x, y, w, h
(x, y, w, h) = cv2.boundingRect(c)
#從mask圖檔中取該四邊形,此即為該物件的shape
roi = mask[y:y + h, x:x + w]
#計算該物件的Zernike moments,半徑r用cv2.minEnclosingCircle指令取得。
features = mahotas.features.zernike_moments(roi, cv2.minEnclosingCircle(c)[1], degree=8)
shapeFeatures.append(features)
#傳回物件及Zernike moments
return (cnts, shapeFeatures)
# 讀取目標圖片
refImage = cv2.imread(args["target"])
refImage = imutils.resize(refImage, height = 120)
#取得Zernike moments
(_, gameFeatures) = describe_shapes(refImage, "Target")
#讀取葉片類表圖片
shapesImage = cv2.imread(args["source"])
#取得Zernike moments
(cnts, shapeFeatures) = describe_shapes(shapesImage, "Sources")
#計算目標圖片和葉片類表中各物件的歐式距離,放到陣列D
D = dist.cdist(gameFeatures, shapeFeatures)
#找到歐式距離最小的那個index
i = np.argmin(D)
#下方是依次將相片中,編號不是i的物件加紅色框。
for (j, c) in enumerate(cnts):
if i != j:
box = cv2.minAreaRect(c)
box = np.int0(cv2.cv.BoxPoints(box))
cv2.drawContours(shapesImage, [box], -1, (0, 0, 255), 2)
#在最相似的葉片編號i加上綠色邊框
box = cv2.minAreaRect(cnts[i])
box = np.int0(cv2.cv.BoxPoints(box))
cv2.drawContours(shapesImage, [box], -1, (0, 255, 0), 2)
(x, y, w, h) = cv2.boundingRect(cnts[i])
#在該葉片附近加上字串”FOUND!”
cv2.putText(shapesImage, "FOUND!", (x, y-3), cv2.FONT_HERSHEY_SIMPLEX, 0.4,
(255, 255, 255), 1)
cv2.imshow("Input Image", refImage)
cv2.imshow("Detected Shapes", shapesImage)
cv2.waitKey(0)
執行結果:
以第一張目標葉片為例,程式會先將圖片轉為binary後計算其Zernike moments,執行過程會顯示轉換後的binary圖片,並將葉片類表中最相近於目標的葉子用綠色框起來。

以下依序為第二至第八張的執行結果:

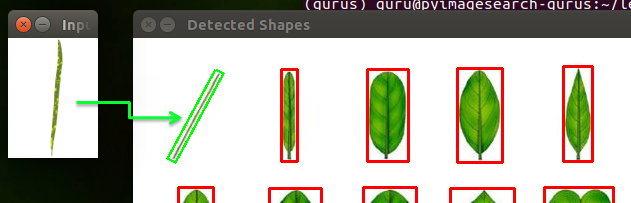
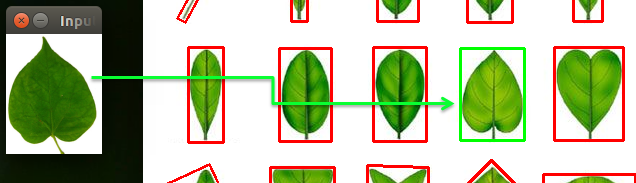
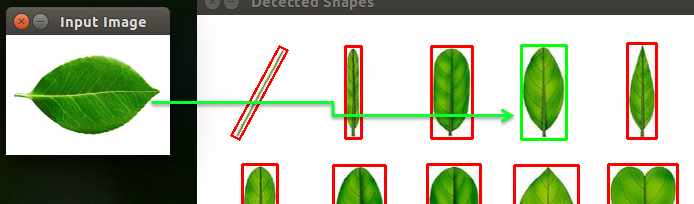
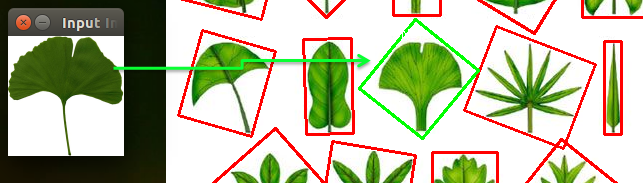

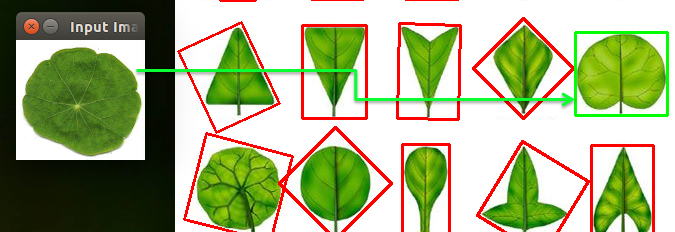
上面的執行結果看似很完美,透過程式分別計算各個物件與目標物件之間的Zernike moments差距(如歐式距離),就能比對出兩個物件是否類似。但其實使用moments有個很大的限制條件,就是它們的外形必須能清楚的分離出來,才能正確計算出moment值,不過在實際生活中,物體並不是一成不變的,不同的角度、方向、動作、光源位置、變形…都會影響到其原本的形態,導致計算結果與實際情況有所誤差,例如下列的情況:

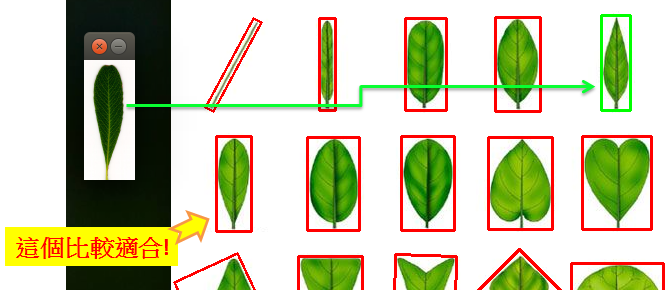
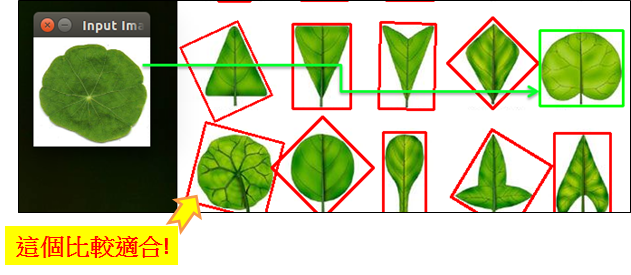
因此建議還是要搭配機器學習的方式,將Moments值作為特徵而非直接使用,如此才能得到最佳的效果。

你必須登入才能發表留言。