

Edge detection邊緣偵測是Computer vision中最重要的步驟,它讓電腦能準確的抓取圖素中的物體,這項技術運用到相當複雜的數學運算,以檢查影像中各像素點的顏色變化程度來區分邊界,限於本人能力,下文並不探討其技術原理,而是實作並熟悉openCV所提供的相關指令。
有了邊緣之後,這些交錯的線段中會有所謂的輪廓,而這也是電腦取得影像中物件的依據。下文中我們也會實作此技術。
Edge detection邊緣偵測
首先,有一個觀念是:邊緣和物體間的邊界並不等同,邊緣指的是圖像中像素的值有突變的地方,而物體間的邊界指的是現實場景中的存在於物體之間的邊界。有可能有邊緣的地方並非邊界,也有可能邊界的地方並無邊緣。
openCV提供三種邊緣檢測方式來處理Edge detection:Laplacian、Sobel及Canny,這些技術皆是使用灰階的影像,基於每個像素灰度的不同,利用不同物體在其邊界處會有明顯的邊緣特徵來分辨。這三種方法皆使用了一維甚至於二維的微分,嚴格來說,若依其使用技術原理的不同可分為兩種:Laplacian原稱為Laplacian method,透過計算零交越點上光度的二階導數(detect zero crossings of the second derivative on intensity changes),而Sobel和Canny使用的則是Gradient methods(梯度原理),它是透過計算像素光度的一階導數差異(detect changes in the first derivative of intensity)來進行邊緣檢測。
兩種方法在使用上也有需要注意的地方,例如Laplacian對於雜訊(Noise)非常敏感,因此在實用上都會將影像先模糊化後再處理(LoG Laplacian of Gaussian)。
Sobel與Canny兩者雖然使用相同的底層技術,但執行方式有些差異。Sobel以簡單的卷積過濾器(convolutional filter)偵測圖像上水平及縱向光度的改變,以加權平均方式計算各點的數值來決定邊緣。Canny則較為複雜,它先將影像模糊化再進行非極大值抑制(non-maxima suppression),因此Canny比起Sobel較能處理雜訊問題,但是需要花費較多的硬體資源來處理。在下方的實作中我們可以看到它們輸出的差異。不過這部份技術原理已超出本人能力範圍無法深入解釋,若您對其技術原理有興趣,可再詳查其相關技術文件。
Laplacian、Sobel與Canny
|
原圖 |
|

我們先看看Laplacian與Sobel,最後再試看看Canny。
首先import必要模組
import numpy as np
import argparse
import cv2
定義一個顯示圖形的function
def displayIMG(img, windowName):
cv2.namedWindow( windowName, cv2.WINDOW_NORMAL )
cv2.resizeWindow(windowName, 1000, 800)
cv2.imshow(windowName, img)
接收輸入的圖片參數
ap = argparse.ArgumentParser()
ap.add_argument(“-i", “–image", required = True, help = “Path to the image")
args = vars(ap.parse_args())
讀取圖片並轉為灰階並顯示
image = cv2.imread(args[“image"])
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
displayIMG(image, “Original")
使用Laplacian找出邊緣。注意使用此函數除了傳入灰階影像之外,亦須指定輸出的影像浮點格式CV_64F,為什麼是使用64bits而非灰階的8bits呢?因為Laplacian過程需進行black-to-white及white-to-black兩種轉換,在微分的梯度計算(gradient)中black-to-white屬於正向的運算而white-to-black則是負向,灰階的8bits格式僅能儲存0-255的正值,因此必須使用64bits。注意在接下來須取其絕對值並轉為8bit的灰階資訊,這是一般在運行Laplacian運算時所建議的方法,網路上的說法是此方式可保留所有的邊緣資訊:先轉出為64bit,再取絕對值轉為8bit。
lap = cv2.Laplacian(image, cv2.CV_64F)
lap = np.uint8(np.absolute(lap))
displayIMG(lap, “Lap")
|
Laplacian |
|

接下來我們來看看Sobel,它可以單獨針對X軸、Y軸或X與Y軸抓取其邊緣。指令是Sobel,第一個參數是灰階圖像,接下來是輸出的資料形態,與Laplacian相同我們一樣設定為浮點資料格式CV_64F,最後是指定要針對X軸、Y軸或X+Y軸運算。
sobelX = cv2.Sobel(image, cv2.CV_64F, 1, 0)
sobelY = cv2.Sobel(image, cv2.CV_64F, 0, 1)
sobelX = np.uint8(np.absolute(sobelX))
sobelY = np.uint8(np.absolute(sobelY))
sobelCombined = cv2.bitwise_or(sobelX, sobelY)
displayIMG(sobelX, “SibelX")
displayIMG(sobelY, “SibelY")
displayIMG(sobelCombined, “SibelXY")
|
Sobel僅針對X軸 |
|
|
Sobel僅針對Y軸 |
|
|
Sobel針對XY軸 |
|



接下來是Canny邊緣檢測,其實Canny不能被單獨稱為一種方法,因為它是一連串的過程加上其它方法,先模糊化去除不必要的像素、再使用類似Sobel方式取得XY軸邊緣。
Canny的使用相當簡單,傳入影像參數並指定兩個門檻參數threshold1與threshold2,意思是,圖形的任一點像素,若其值大於threshold2,則認定它屬於邊緣像素,若小於threshold1則不為邊緣像素,介於兩者之間則由程式依其像素強度值運算後決定。
canny = cv2.Canny(image, 30, 150)
displayIMG(canny, “Canny")
|
Canny |
|

CONTOURS輪廓
使用上述三種方法找出邊緣後,接下來就是確定Contours輪廓了。Contours是由一連串沒有間斷的點所組成的曲線,我們在針對影像進行分析及識別時,Contours的使用是很重要的一個步驟。
cv2.drawContours可協助我們找出Contours,下方我們暫且不用前面的座位空拍圖,而先用一張較為單純的相片來作示範,看看如何利用OpenCV來抓取物件。先在桌上放了幾枚壹圓、伍圓、拾圓的硬幣,然後用我的iPhone 4手機拍下如下的相片,我們試看看可否透過OpenCV抓出相片中的硬幣。
首先照例先載入必要的class,並定義一個顯示圖片的function。
import numpy as np
import imutils
import cv2
def displayIMG(img, windowName):
cv2.namedWindow( windowName, cv2.WINDOW_NORMAL )
cv2.resizeWindow(windowName, 600, 600)
cv2.imshow(windowName, img)
1.讀取圖檔:讀取圖片檔並顯示:
image = cv2.imread(args[“image"])
displayIMG(image, “Original")

2.高度縮小為450,寬度也等比例縮小。
r = 450.0 / image.shape[0]
dim = (int(image.shape[1] * r), 450)
resized = cv2.resize(image, dim, interpolation=cv2.INTER_AREA)
displayIMG(resized, “Resized")

3.轉換為灰階
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
displayIMG(gray, “Gray")

4.模糊化(使用高斯模糊)
blurred = cv2.GaussianBlur(gray, (11, 11), 0)
displayIMG(blurred, “Blur")

5.使用Canny方法尋找邊緣
edged = cv2.Canny(blurred, 30, 150)
displayIMG(edged, “Edged")
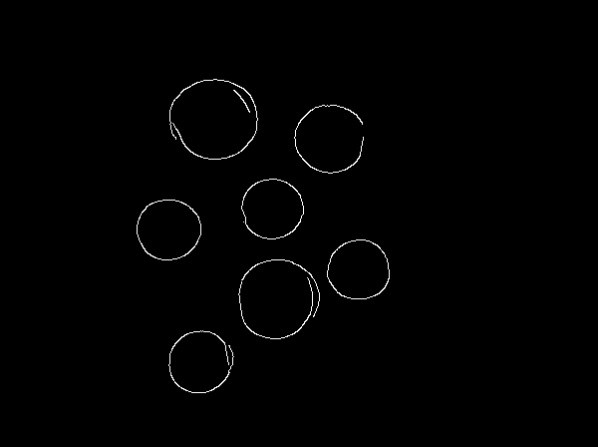
5.確定輪廓
(_, cnts, _) = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
print(“I count {} coins in this image".format(len(cnts)))
coins = resized.copy()
cv2.drawContours(coins, cnts, -1, (0, 255, 0), 2)
displayIMG(coins, “Coins")

參數中cv2.RETR_EXTERNAL是指我們只取最外層的輪廓,cv2.CHAIN_APPROX_SIMPLE是指水平垂直對角等線中只取最終點來計算,可節省記憶體及加快運算時間。另外,cv2.findContours會傳回三組資料,第一個為修改過的圖檔,第二個為找到的Contours資料(Python格式的list,所以用len函式所回傳的值便是Contour數目),第三個為Contours的階層資訊(此第三筆資訊僅在OpenCV 3才支援)。
5.取出圖形
利用cv2.boundingRect可取出Contour的圖形,該函數會回傳每個Contour左上角的坐標值及長寬值。
for (i, c) in enumerate(cnts):
(x, y, w, h) = cv2.boundingRect(c)
print(“Coin #{}".format(i + 1))
coin = resized[y:y + h, x:x + w]
cv2.imshow(“Coin", coin)
mask = np.zeros(resized.shape[:2], dtype = “uint8″)
((centerX, centerY), radius) = cv2.minEnclosingCircle(c)
cv2.circle(mask, (int(centerX), int(centerY)), int(radius), 255, -1)
mask = mask[y:y + h, x:x + w]
displayIMG(cv2.bitwise_and(coin, coin, mask = mask), “Masked Conis")







